개요
지난번에는 [Kubernetes Deep Dive] 쿠버네티스 네트워크를 통해서 쿠버네티스 클러스터 내부에서 어떻게 패킷이 이동하고 서로 통신할 수 있는지를 간단하게 설명했었습니다. 이번에는 우리가 쿠버네티스를 사용하면서 항상 보고있지만 정확히는 모르겠는 kube-proxy라는 컴포넌트가 무엇인지, 어떻게 동작하는지에 대해서 정리해보고자 합니다.
Service
kube-proxy에 설명하기에 앞서서 Service는 무엇인지에 대해서 설명해 보도록 하겠습니다.
우리는 쿠버네티스에서 Pod란 언제든지 종료될 수 있고 재생성될 수 있기에 일시적인 존재라는 것을 알고 있습니다. 새로운 Pod가 생성되면 이전 Pod의 IP와는 별개의 IP를 할당받게 되며 이로 인해서 우리는 Pod의 IP에 의존할 수 없었습니다.
이러한 문제를 해결하고자 Service가 등장하였습니다. Service는 여러 Pod에게 Stable한 IP와 DNS 이름을 제공하는 역할을 하며, 이로 인해 Pod는 종료되거나 재생성되어도 어플리케이션이 잘 동작할 수 있었던 것입니다.
또한 Service는 Pod 간의 트래픽을 분산하여 요청이 균등하게 분산되고 개별 Pod가 과부하되지 않도록 보장해 줍니다. 우리는 이를 통해서 고가용성 및 확장성 애플리케이션을 만들 수 있게 되었습니다.
그런데 Service와 Pod의 관계는 어떻게 유지될 수 있는 걸까요? 바로 여기서 kube-proxy가 등장하게 됩니다.
kube-proxy는 Service IP 주소를 해당 Service에 속한 Pod의 IP 주소에 매핑하는 네트워크 라우팅 테이블을 유지함으로써 Service-Pod 간 매핑을 지원해 줍니다. 새로운 Service에 대한 요청이 오면, kube-proxy는 이 정보를 매핑하여 패킷이 Service에 속한 Pod로 전달될 수 있도록 해줍니다.
Kube-Proxy
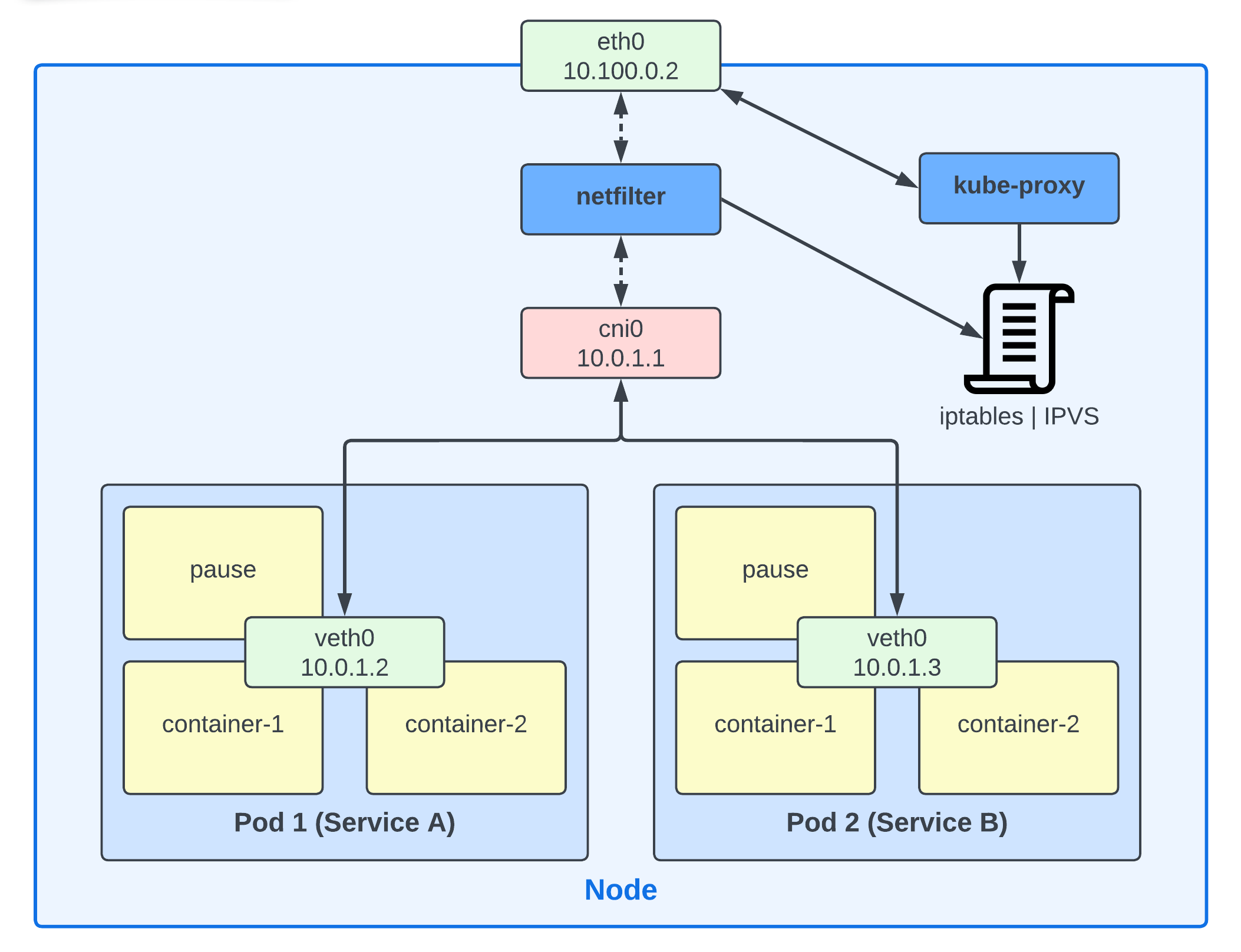
위에서 설명했듯 kube-proxy는 뒤편에서 Service나 Endpoint(Pod IP)에 변경이 발생하면 변경 사항을 Node안에서 실제 사용 가능한 네트워크 룰로 변환해 주는 역할을 해주는 에이전트입니다.
이 에이전트는 클러스터내의 모든 노드에 설치되며 주로 DaemonSet으로 동작합니다. 물론 이 방법뿐만 아니라 노드에 프로세스로 직접 설치할 수 도 있습니다.
Kube-Proxy는 어떻게 동작하는가
Kube-Proxy가 설치되면 API Server와 인증을 설정합니다. 그리고 새로운 Service나 Endpoint(Pod IP)가 생성 및 삭제되었을 때, 이러한 변경 사항을 API Server로부터 전달받습니다.
그러고 kube-proxy는 이러한 변경사항을 Node의 NAT 룰로 적용시킵니다. 이 NAT 룰은 단순히 Service IP와 Pod IP를 매핑해 줍니다. Service를 대상으로 요청이 왔을 때, 이 룰이 백엔드 Pod로 Redirect 해줍니다.
예시와 함께 조금 더 자세히 설명해 보도록 하겠습니다.
app: X 라는 label을 가진 Pod를 대상으로 ServiceX를 생성해보도록 하겠습니다. 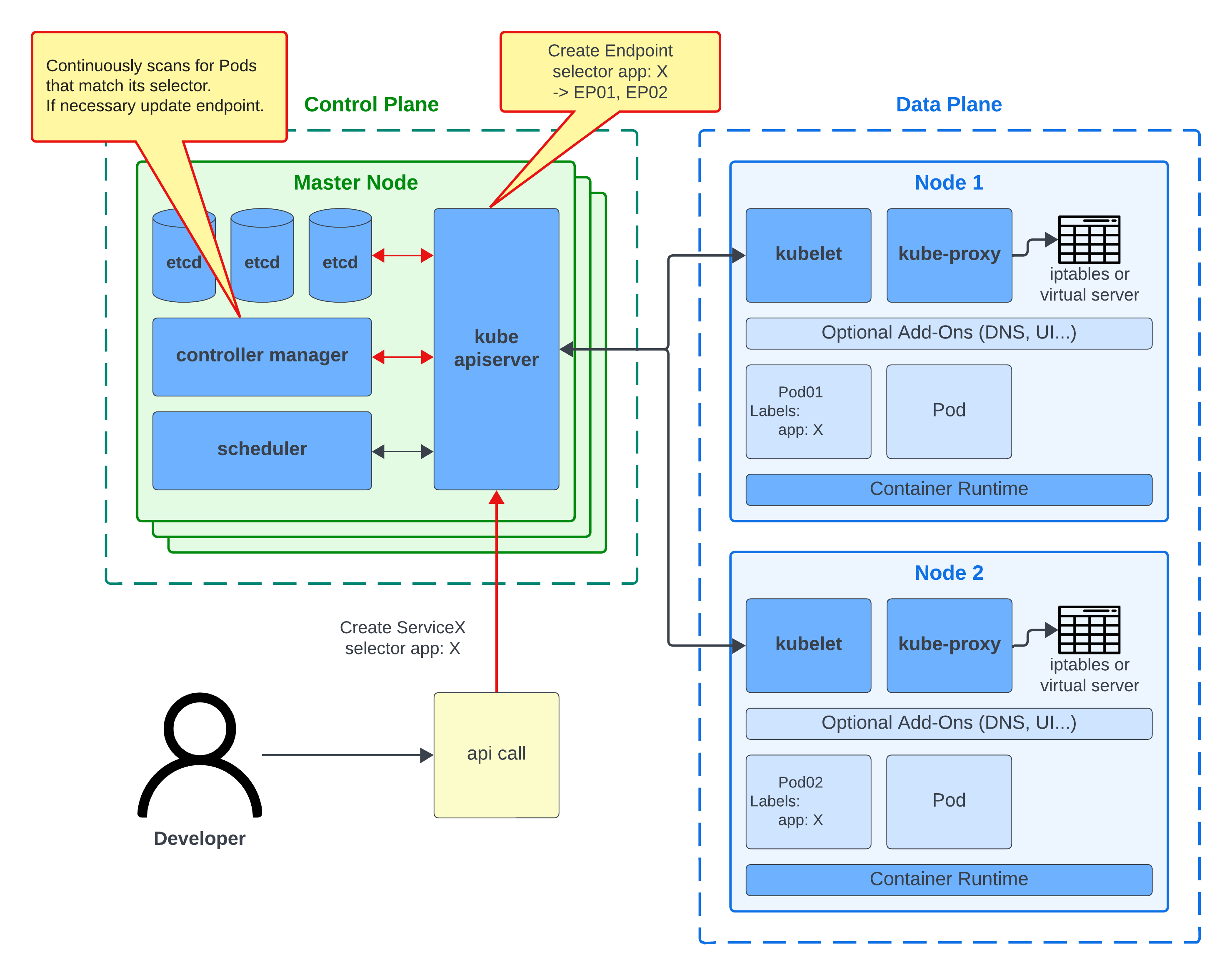
먼저 API Server가 Create ServiceX 요청을 받게되면 Service 오브젝트를 생성하고 IP를 부여합니다. 그리고 Endpoint 오브젝트를 생성하여 지정한 app: X와 동일한 label을 가진 Pod의 IP를 저장합니다. (실제로 이 Endpoint가 Service가 트래픽을 전달하고자 하는 Pod의 집합입니다.)
마지막으로 Enpoint Controller가 API Server를 통해서 지속적으로 변경사항이 없는지 확인하며, 필요할 경우 Endpoint를 업데이트합니다.
이러한 특징을 이용하여 Endpoint 오브젝트를 직접 생성해 매뉴얼하게 IP 주소를 넣어줄 수 있습니다. 예를들면 Service 이름을 통해서 쿠버네티스 외부 서버나 DB등을 접근하게 할 수 있는 것이죠.
관심이 있다면 https://yoo11052.tistory.com/193 를 참고해보면 좋을 것 같습니다.
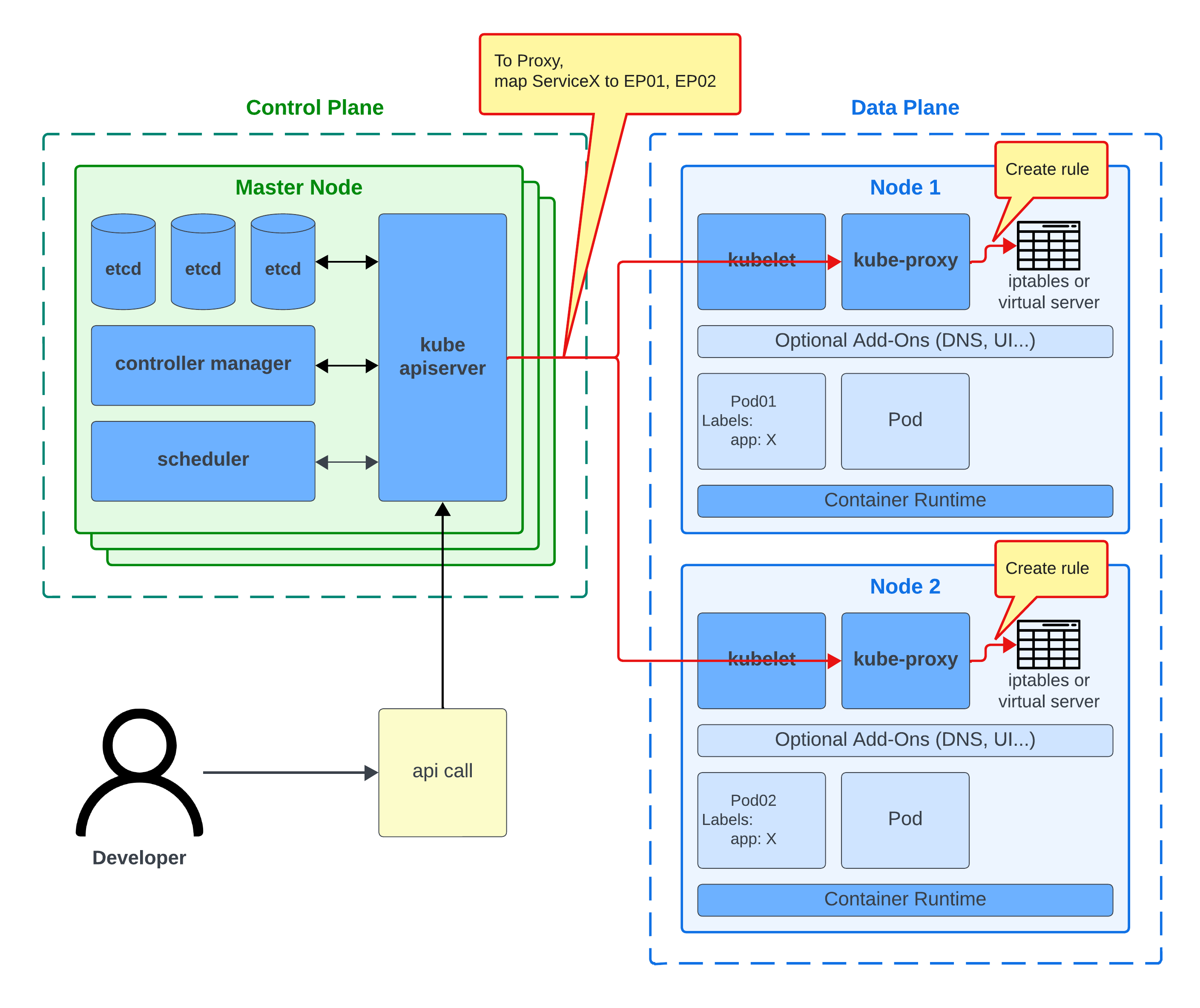 이러한 변경사항이 일어난 이후, API Server는 새로운 매핑정보를 각 Node의 Kube-Proxy에게 알립니다. 그리고 Kube-Proxy는 이러한 변경사항을 각 Node의 DNAT rule로 등록합니다.
이러한 변경사항이 일어난 이후, API Server는 새로운 매핑정보를 각 Node의 Kube-Proxy에게 알립니다. 그리고 Kube-Proxy는 이러한 변경사항을 각 Node의 DNAT rule로 등록합니다.
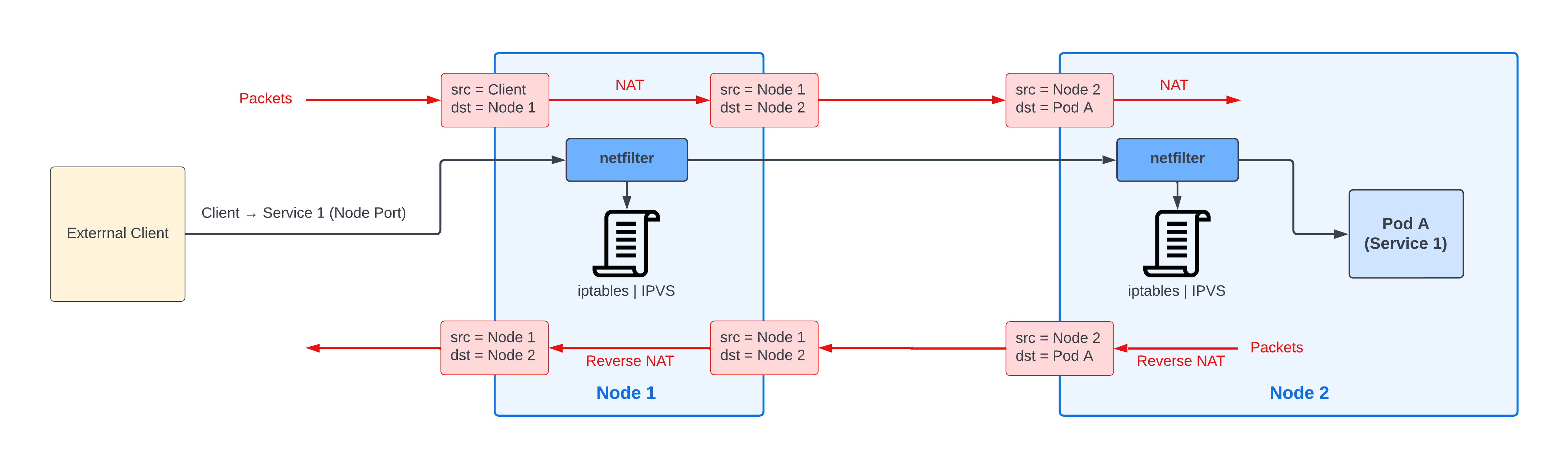 이를 통해 ServiceX에 대한 요청은 NAT 룰을 거쳐 대상 Pod로 포워딩될 수 있게 됩니다.
이를 통해 ServiceX에 대한 요청은 NAT 룰을 거쳐 대상 Pod로 포워딩될 수 있게 됩니다.
물론 이 시나리오는 단순화시킨 것입니다. 몇 가지 짚고 넘어가야 할 사항을 꼽자면,
- Service와 Endpoint는 IP만이 아닌 IP와 Port의 매핑입니다.
- 다른 유형의 Service를 사용하는 경우, 노드 내부에 예시와는 다른 규칙이 설치될 수 있습니다.
Kube-Proxy Modes
Kube-Proxy는 user-space mode, IPtables mode 그리고 IPVS mode 의 3가지 모드로 동작할 수 있습니다. 각각의 모드는 Kube-Proxy가 어떻게 NAT rule을 적용하는가에 따라 나뉘어 있습니다.
아래를 통해 각각의 모드에 대해서 간략하게 설명하도록 하겠습니다.
User-Space Mode
해당 모드는 거의 사용되지 않는 레거시 모드입니다. 이 모드에서는 Linux의 IPtables 기능을 이용합니다. 하지만 NAT 룰을 통해 local Kube-Proxy에 redirect 시키고 Kube-Proxy가 직접 이 요청을 포워딩하게 합니다. 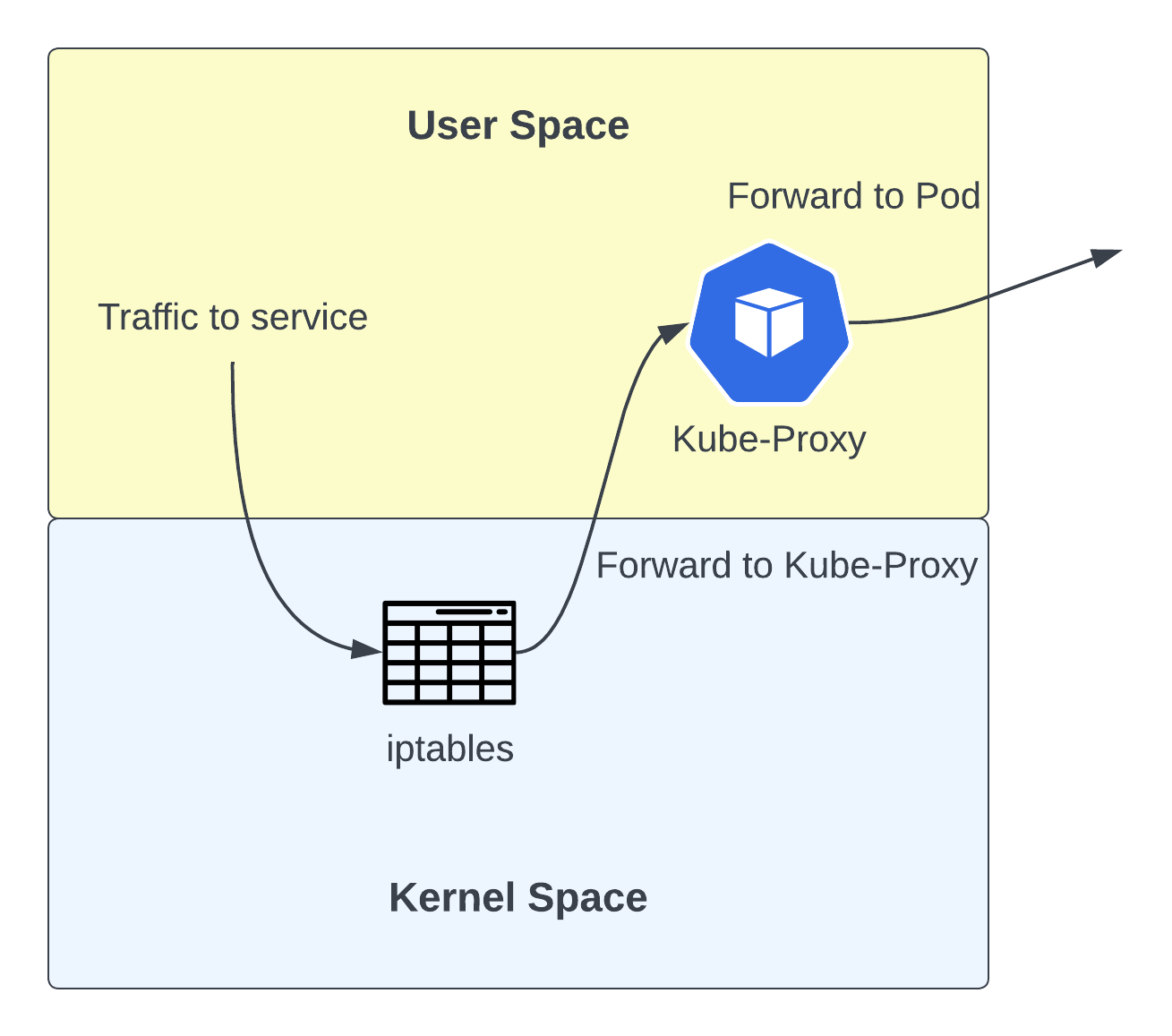 이 모드의 단점은 트래픽을 두 번 리디렉션해야 한다는 것입니다. 이는 지연 시간과 처리량에 부정적인 영향을 미치게 됩니다.
이 모드의 단점은 트래픽을 두 번 리디렉션해야 한다는 것입니다. 이는 지연 시간과 처리량에 부정적인 영향을 미치게 됩니다.
IPtables Mode
이 모드는 Default 모드로 현재 가장 넓게 사용되고 있습니다. 이 모드 또한 User-Space 모드와 동일하게 Linux 커널의 IPtables를 사용하고 있습니다. 하지만 Kube-Proxy로 요청을 보내는 것이 아닌 바로 대상 Pod로 트래픽을 전달합니다.
Kube-Proxy가 기존의 Proxy 역할을 하는 대신, IPTables에 Rule을 넣어주는 역할을 하게 되면서 traffic을 처리하는 것에 대한 부담이 없어지게 되었습니다. 이는 User-Space 모드와 비교하여 레이턴시를 줄여줄 수 있었습니다.
추가적으로 이 변화로 인해 kube-proxy의 역할은 더 이상 proxy가 아닌 installer에 가까워졌습니다. 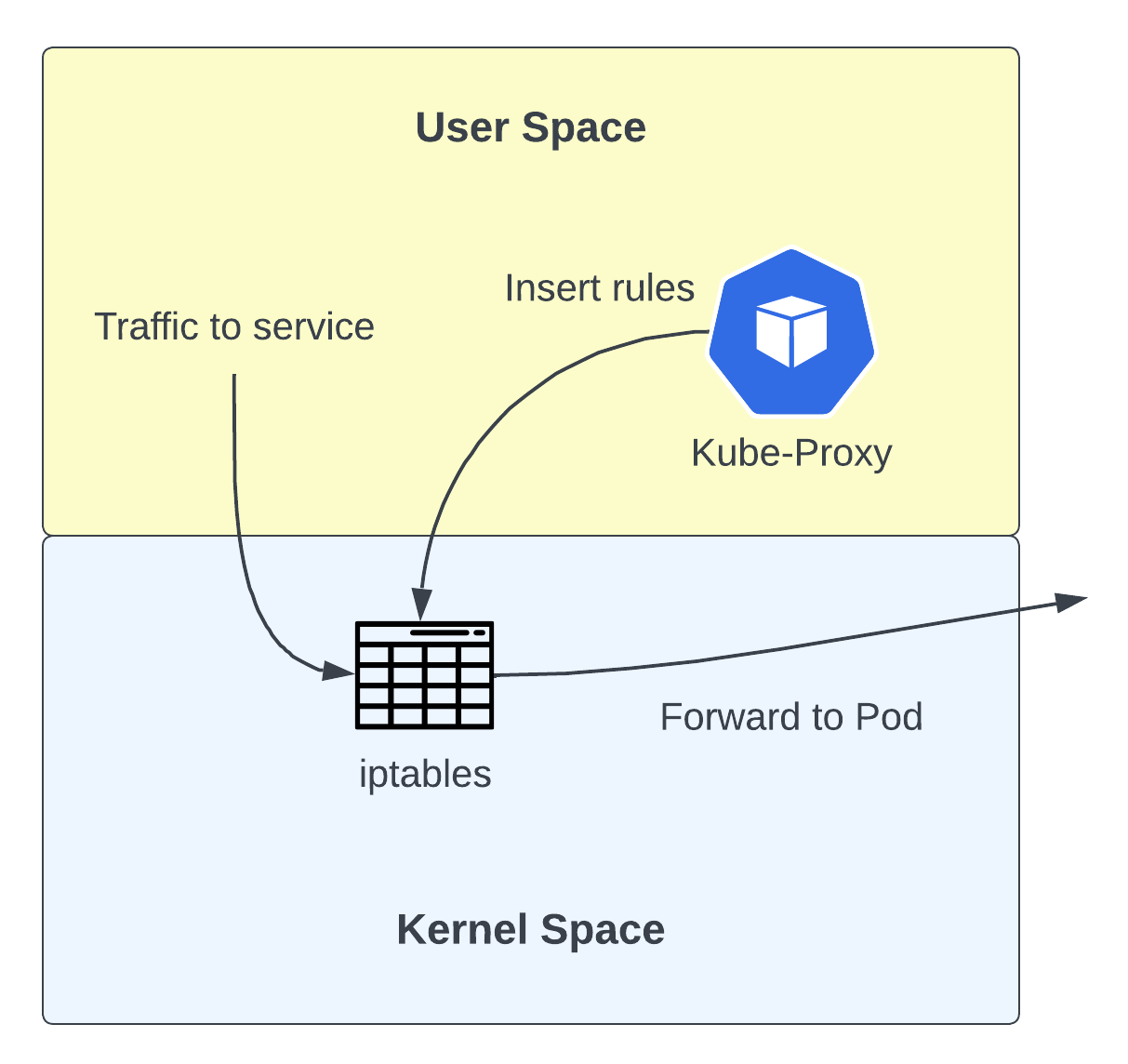 해당 모드의 단점은 기존 IPtables의 알고리즘입니다. IPtables는 lookup시에 순차적으로 규칙을 조회합니다. 이는 O(n) 성능을 가진다는 것을 말하며, 규칙의 수가 많아지면 조회 횟수가 선형적으로 증가한다는 것을 의미합니다.
해당 모드의 단점은 기존 IPtables의 알고리즘입니다. IPtables는 lookup시에 순차적으로 규칙을 조회합니다. 이는 O(n) 성능을 가진다는 것을 말하며, 규칙의 수가 많아지면 조회 횟수가 선형적으로 증가한다는 것을 의미합니다.
또한 IPtables가 로드 밸런싱 알고리즘을 지원하지 않는다는 점 또한 단점으로 작용할 수 있습니다.
IPVS Mode
IPVS는 로드밸런싱을 위해 특별히 설계된 Linux 커널의 기능입니다. 이 모드에서는 Kube-Proxy가 IPtables 대신 IPVS에 규칙을 추가합니다.
IPVS는 O(1)의 복잡도를 가진 알고리즘을 가지고 있습니다. 즉, 규칙의 수와 상관없이 일정한 성능을 제공합니다. 또한 라운드 로빈, 최소 연결 및 기타 부하 분산 알고리즘도 지원합니다.
더 자세히 성능을 비교한 내용은 iptables-or-ipvs 에서 확인할 수 있습니다.
하지만 아직 모든 Linux 시스템에서 제공되고 있지는 않습니다. 그리고 만약 Service의 수가 많지 않다면 IPtables 방식 또한 잘 동작하기에 반드시 써야되는 방식은 아닙니다.